La mode est aux frameworks Javascript côté client et, dans ce monde en pleine effervescence, trois frameworks se battent pour la première place: Backbone, EmberJS et Angular. Angular est celui qui a le plus le vent en poupe en ce moment de par sa simplicité d’apprentissage et la richesse de ses fonctionnalités. Chez Xebia, nous sommes plusieurs développeurs à utiliser ce framework sur différents projets. Nous allons donc partager avec vous notre connaissance concrète et nos bonnes pratiques.
Dans ce premier article, mon objectif est de vous faire mieux comprendre les fondations d’AngularJS car, si ses tutoriels et ses démos sont toujours impressionnants, beaucoup de personnes bloquent sur les premiers éléments de complexité qui le font apparaître comme magique. La cause vient principalement de la documentation qui, bien que complète, n’est souvent pas assez didactique. Le manque de conventions du framework peut aussi être déroutant.
En fait la courbe d’apprentissage d’AngularJS est très bien représentée sur cette illustration trouvée sur Internet.

Dernière remarque à propos de cet article, il n’y aura que peu de code car ce n’est pas un tutoriel d’introduction. Il y en a déjà plein sur Internet dont le très efficace Phonecat. L’objectif est plus de comprendre certains concepts sur lesquels se base Angular.
Un Framework Modèle Vue Contrôleur
AngularJS est donc un framework qui se veut Model-View-Whatever ou, pour simplifier, qui suit classiquement la logique MVC afin de séparer la logique de présentation de la logique métier et de son état.
Nous avons donc la vue qui est directement notre code HTML, des contrôleurs et un élément appelé Scope qui s’apparente au modèle.
Vue et « Two-Way Data Binding »
Lorsqu’on utilise Angular, on code la vue directement dans des fichiers HTML qui vont représenter soit les pages de notre application, soit des sous-ensembles de ces pages. Le framework se base donc sur une approche clairement déclarative de la construction d’une interface utilisateur et suit donc pleinement la logique HTML. L’objectif est même d’étendre HTML et de créer son propre DSL. La force de cette approche est clairement de pouvoir fournir de nouveaux éléments au navigateur qui pourront être réutilisés facilement dans l’application web et même dans d’autres applications. Pour information, cette approche est très proche voir identique au Web Component, norme de construction d’application HTML5 proposé au W3C, dont une première implémentation serait Polymer.
En fait, Angular contient tout simplement un compilateur HTML qui va parcourir votre page en identifiant les éléments purement HTML, les expressions (éléments dynamiques textuels simples) et les directives (éléments d’UI plus complexes dont ceux fournis par Angular sont préfixés par « ng- ») pour créer un nouveau DOM qui sera lié aux données par l’intermédiaire du Scope et du contrôleur.
La phase de compilation traverse le DOM pour enregistrer toutes les expressions et directives et fournit en résultat une fonction de « linking ». La phase d’assemblage (ou link) combine l’ensemble avec le Scope pour produire une vue dynamique (celle qui s’affiche dans votre navigateur). Séparer les phases de compilation et d’assemblage permet d’améliorer les performances quand on veut par exemple générer une vue complexe (à l’instar de la directive ng-repeat).
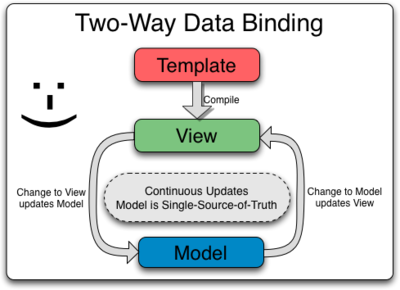
Cette architecture permet de créer un « Two-Way Data Binding ». Cette liaison de données bidirectionnelle se réfère à la capacité de lier les modifications apportées aux propriétés d’un objet à des changements dans l’interface utilisateur, et vice-versa. En d’autres termes, si nous avons un objet « user » avec une propriété « name », chaque fois que nous assignons une nouvelle valeur à « user.name » l’interface utilisateur doit indiquer le nouveau nom. De la même manière, si l’interface utilisateur comprend un champ de saisie pour le nom de l’utilisateur, entrer une valeur fait que la propriété « name » de l’objet « user » doit être modifiée en conséquence.
Pour donner un exemple concret, on va prendre le code simpliste suivant:
<!doctype html>
<html ng-app>
<head>
<script src="http://code.angularjs.org/1.2.0-rc.2/angular.min.js"></script>
</head>
<body>
<input type="text" ng-model="name">
<p>Hello {{ name }}!</p>
</body>
</html>
Notre modèle est constitué de la propriété « name » et grâce à la directive input, celui-ci est mis à jour dès que l’utilisateur interagit avec le champ texte. La syntaxe « {{ name }} » au sein du HTML permet d’afficher la valeur de la propriété « name » du modèle. Le « Two-Way Data Binding » assure que le texte est instantanément mis à jour lorsque l’utilisateur modifie le champ !
Contrôleur et Modèle
Le modèle est l’ensemble des données qui sont accessibles par un objet Javascript Angular, nommé Scope. Il y a différents endroits où l’on peut créer des données et les initialiser, directement dans des expressions, par l’intermédiaire de la directive ng-model et bien sûr dans le contrôleur. Le contrôleur et le Scope sont deux éléments liés. Le contrôleur est là pour augmenter le Scope en y initialisant ses données ou en y ajoutant des comportements et pour cela, il « applique » (avec la fonction Javascript Apply) le constructeur du contrôleur à un nouvel objet Scope. Plusieurs façons existent pour déclarer un contrôleur mais la meilleure, qui permet la minification du code JS, est celle-ci :
myApp.controller('MyCtrl', ['$scope', function($scope) {
$scope.greeting = 'Hello World!';
}]);
Le Scope correspond au contexte Javascript au sein duquel les expressions sont évaluées. En fait une application Angular est constituée d’un ensemble de Scopes associés à un contrôleur qui vont être organisés sous forme d’un arbre (des vues, des sous vues, etc). Il y a un d’ailleurs un $rootScope associé à l’application Angular qui est la racine de l’ensemble des Scopes. Même si ce $rootScope vous permet de stocker des variables communes à l’ensemble de l’application, je vous conseille d’éviter cette pratique et de passer plutôt par un Service (nous verrons les services dans un autre article).
Voila ce que ça donne, par exemple, dans le schéma ci-dessous en sachant que le $scope au niveau de la directive ng-app est le $rootScope./p>
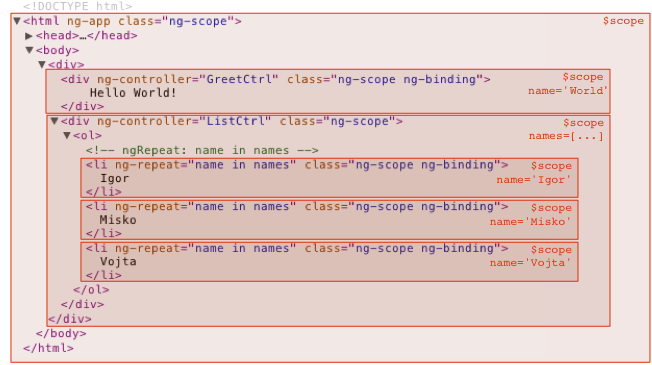
Un point important à connaitre, lorsque l’on crée une sous vue, est que le Scope associé à cette sous vue hérite du Scope de la vue parente. Cet héritage suit la logique prototype de JS, ce qui entraîne des contraintes telles que seules les fonctions et les objets javascript présents dans le Scope parent sont utilisables par ses Scopes fils. Angular conseille d’ailleurs de toujours utiliser des objets pour représenter le modèle et éviter de travailler directement avec des primitives. Pour plus d’information le wiki d’Angular offre une documentation complète de l’héritage des scopes.
Le Scope nous fournit principalement les fonctions $watch pour observer les changements du modèle et $apply pour propager un changement du modèle de l’extérieur, par exemple une directive associée à JQuery, vers le contexte Angular.
C’est dans le cycle de vie du Scope que se fait le « dirty checking » qui assure le « Two-Way Data Binding ». Plus précisément la phase de $digest examine toutes les variables surveillées par un $watch, les compare par rapport à leurs valeurs précédentes et met à jour la vue en fonction de cette comparaison. Pour ceux qui auraient des doutes au sujet des performances, il y a encore une très bonne réponse sur stackoverflow.
Enfin, le Scope offre aussi la possibilité de transmettre des évènements dans cet arbre ($broadcast pour aller vers les fils, $emit pour aller vers les parents et $on pour écouter les messages).
N’hésitez pas à aller lire cette page dans la documentation car le Scope est une des pierres angulaires d’Angular (sans jeu de mot !).
Cycle de vie d’une application AngularJS
Dans cette dernière partie, nous allons rentrer un peu plus dans le cycle de vie d’une application Angular.
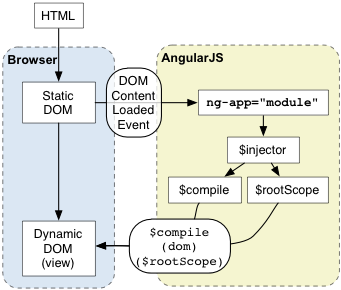
À l’initialisation de l’application :
- Le navigateur charge le HTML, le transforme en DOM et charge le javascript d’Angular.js
- Angular attend l’évènement DOMContentLoaded, puis cherche une directive nommée ng-app qui définit les frontières de l’application
- Le service d’injection ($injector) est alors utilisé pour créer le $rootScope et le service $compile qui va compiler le DOM et le lier au $rootScope.
- Les éléments dynamiques tels que les expressions sont alors rendus
Et au runtime :
- la boucle d’évènement du navigateur attend qu’un évènement arrive, un évènement étant une interaction de l’utilisateur, la fin d’un timer ou la réponse d’un serveur.
- la callback de l’évènement est exécutée. On entre alors dans le contexte Javascript. Cette callback peut modifier la structure du DOM.
- une fois que la callback s’est exécutée, le navigateur quitte le contexte Javascript et rend la vue basée sur les changements du DOM
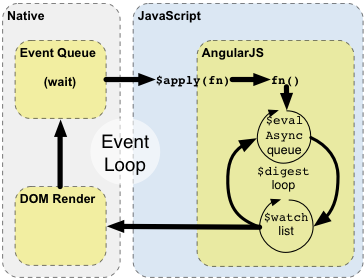
Le monde Angular est constitué d’une boucle de $digest elle-même composée de deux boucles ($evalAsync et $watch) qui vont évaluer l’ensemble des changements sur le modèle. En fait, la boucle $digest continue de se répéter tant que la queue $evalSync n’est pas vide et que le $watch ne détecte plus de changement. Dès que cette boucle $digest est finie, on sort alors du contexte Angular et Javascript et le navigateur ré-affiche le DOM mis à jour.
En reprenant l’exemple précédent :
<!doctype html>
<html ng-app>
<head>
<script src="http://code.angularjs.org/1.2.0-rc.2/angular.min.js"></script>
</head>
<body>
<input type="text" ng-model="name">
<p>Hello {{ name }}!</p>
</body>
</html>
Pendant la phase de compilation :
- la directive associée à <input> ajoute un observateur sur l’appui d’une touche
- l’expression {{ name }} place un $watch pour suivre les changements sur la propriété « name » du modèle
Pendant la phase d’exécution :
- appuyer sur la touche ‘A’ dans le champ <input> fait que le navigateur émet un évènement de type KeyDown
- la directive input écoute ce changement et appelle $apply(« name = ‘A’; ») pour mettre à jour le modèle
- la boucle $digest parcourt la liste de $watch, détecte le changement de la propriété « name » et en informe l’expression {{ name }} qui met à jour le DOM
- on sort du $digest, du contexte d’exécution Angular et Javascript, le navigateur rend la page avec le texte mis à jour
Angular modifie donc le flot d’exécution normal du Javascript en fournissant sa propre boucle d’évènement. Cela divise le javascript en un contexte d’exécution classique et celui d’Angular. Seules les opérations qui sont appliquées dans le contexte d’exécution d’Angular bénéficient du framework. C’est pourquoi, dans une directive, on doit régulièrement utiliser la fonction $apply pour la relier au contexte d’exécution d’Angular.
Par exemple, avec une version simplifiée de la directive ng-click :
link: function(scope, element, attr) {
var callback = $parse(attr.ngClick);
element.on('click', function() {
scope.$apply(function() {
callback(scope);
});
});
};
Voilà, nous avons une vision un peu plus claire et précise du fonctionnement d’AngularJS qui va nous permettre de mieux comprendre le framework, d’éviter quelques pièges et surtout d’appréhender sans trop de difficulté la création de nos propres directives.
N’hésitez pas à venir poser vos questions dans les commentaires!